The Final Word Guide To Deepseek
페이지 정보

본문
Innovations: Deepseek Coder represents a major leap in AI-pushed coding models. DeepSeek Coder helps business use. Free for business use and fully open-source. In addition, we perform language-modeling-primarily based evaluation for Pile-take a look at and use Bits-Per-Byte (BPB) because the metric to guarantee truthful comparison amongst fashions using different tokenizers. SWE-Bench verified is evaluated using the agentless framework (Xia et al., 2024). We use the "diff" format to judge the Aider-related benchmarks. Reference disambiguation datasets embrace CLUEWSC (Xu et al., 2020) and WinoGrande Sakaguchi et al. We curate our instruction-tuning datasets to include 1.5M cases spanning a number of domains, with every area employing distinct knowledge creation strategies tailor-made to its particular necessities. "A main concern for the way forward for LLMs is that human-generated knowledge might not meet the growing demand for high-high quality knowledge," Xin stated. DeepSeekMoE is an advanced version of the MoE structure designed to improve how LLMs handle complex duties. Exploring Code LLMs - Instruction nice-tuning, models and quantization 2024-04-14 Introduction The purpose of this submit is to deep seek-dive into LLM’s which might be specialised in code era duties, ديب سيك and see if we will use them to put in writing code. Upon finishing the RL training phase, we implement rejection sampling to curate excessive-high quality SFT information for the ultimate model, the place the expert models are used as data technology sources.
Throughout the RL section, the model leverages high-temperature sampling to generate responses that integrate patterns from each the R1-generated and unique data, even within the absence of explicit system prompts. The 7B model utilized Multi-Head consideration, while the 67B model leveraged Grouped-Query Attention. The LLM was educated on a large dataset of 2 trillion tokens in both English and Chinese, using architectures equivalent to LLaMA and Grouped-Query Attention. The analysis extends to by no means-earlier than-seen exams, including the Hungarian National High school Exam, the place DeepSeek LLM 67B Chat exhibits outstanding performance. In the prevailing course of, we have to read 128 BF16 activation values (the output of the previous computation) from HBM (High Bandwidth Memory) for quantization, and the quantized FP8 values are then written again to HBM, solely to be learn again for MMA. Our goal is to balance the high accuracy of R1-generated reasoning data and the readability and conciseness of often formatted reasoning knowledge. For non-reasoning data, such as artistic writing, position-play, and easy question answering, we make the most of DeepSeek-V2.5 to generate responses and enlist human annotators to confirm the accuracy and correctness of the info. Von Werra, of Hugging Face, is engaged on a project to totally reproduce DeepSeek-R1, including its data and training pipelines.
Finally, the training corpus for DeepSeek-V3 consists of 14.8T high-high quality and numerous tokens in our tokenizer. Each MoE layer consists of 1 shared expert and 256 routed specialists, where the intermediate hidden dimension of every knowledgeable is 2048. Among the routed specialists, eight specialists will probably be activated for each token, and every token will likely be ensured to be sent to at most four nodes. We leverage pipeline parallelism to deploy different layers of a model on totally different GPUs, and for every layer, the routed experts will probably be uniformly deployed on sixty four GPUs belonging to eight nodes. When data comes into the mannequin, the router directs it to the most applicable experts based mostly on their specialization. Also, our knowledge processing pipeline is refined to reduce redundancy whereas sustaining corpus variety. Through this two-phase extension training, DeepSeek-V3 is capable of handling inputs as much as 128K in length whereas sustaining sturdy performance. While encouraging, there is still much room for enchancment. As for Chinese benchmarks, apart from CMMLU, a Chinese multi-topic a number of-selection task, DeepSeek-V3-Base also shows better performance than Qwen2.5 72B. (3) Compared with LLaMA-3.1 405B Base, the most important open-source model with eleven instances the activated parameters, DeepSeek-V3-Base also exhibits significantly better efficiency on multilingual, code, and math benchmarks.
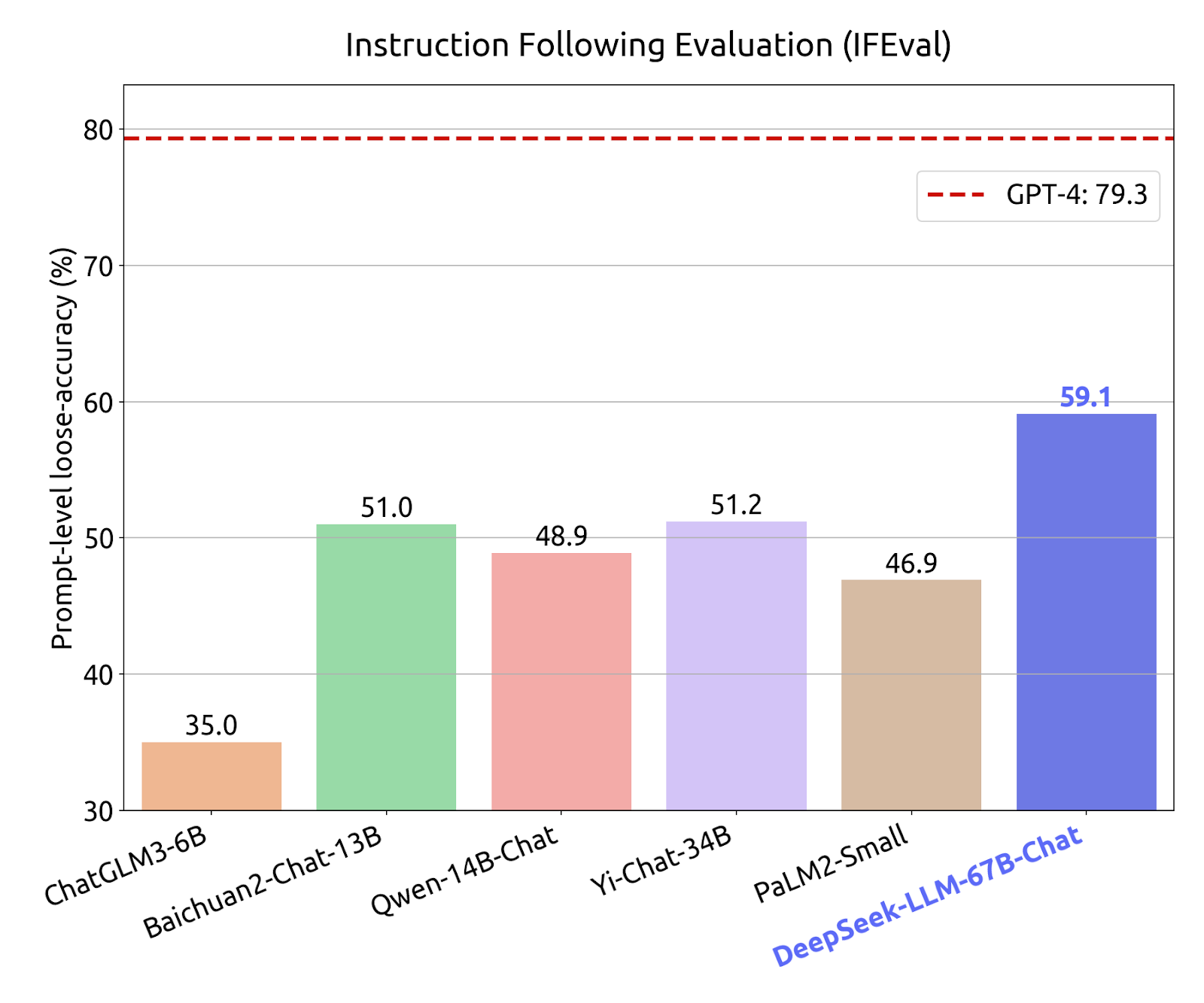
- 이전글Demo Ultimate Striker PG SOFT Bet Besar 25.02.01
- 다음글Need to Step Up Your Deepseek? It's Worthwhile to Read This First 25.02.01
댓글목록
등록된 댓글이 없습니다.