9 Methods To enhance Deepseek
페이지 정보

본문
 Since you might be utilizing it, you've gotten no doubt seen folks talking about DeepSeek AI, the new ChatBot from China that was developed at a fraction of the costs of others prefer it. If I have something useful I can refactor and improve it, but I can’t go straight from zero to a quality project. I keep my motivation much better when my mission is practical at each step. But after i get them, deepseek coder’s code is slightly better than chatgpt or Gemini. LLMs match into this picture as a result of they can get you instantly to something functional. Share this text with three associates and get a 1-month subscription free! Subscribe at no cost to receive new posts and support my work. Olama is totally free. While still in its early stages, this achievement signals a promising trajectory for the development of AI models that may perceive, analyze, and clear up advanced issues like people do. As DeepSeek continues to evolve, its influence on AI growth and the industry at massive is undeniable, providing powerful instruments for companies, builders, and individuals alike. It went from being a maker of graphics playing cards for video games to being the dominant maker of chips to the voraciously hungry AI industry.
Since you might be utilizing it, you've gotten no doubt seen folks talking about DeepSeek AI, the new ChatBot from China that was developed at a fraction of the costs of others prefer it. If I have something useful I can refactor and improve it, but I can’t go straight from zero to a quality project. I keep my motivation much better when my mission is practical at each step. But after i get them, deepseek coder’s code is slightly better than chatgpt or Gemini. LLMs match into this picture as a result of they can get you instantly to something functional. Share this text with three associates and get a 1-month subscription free! Subscribe at no cost to receive new posts and support my work. Olama is totally free. While still in its early stages, this achievement signals a promising trajectory for the development of AI models that may perceive, analyze, and clear up advanced issues like people do. As DeepSeek continues to evolve, its influence on AI growth and the industry at massive is undeniable, providing powerful instruments for companies, builders, and individuals alike. It went from being a maker of graphics playing cards for video games to being the dominant maker of chips to the voraciously hungry AI industry.
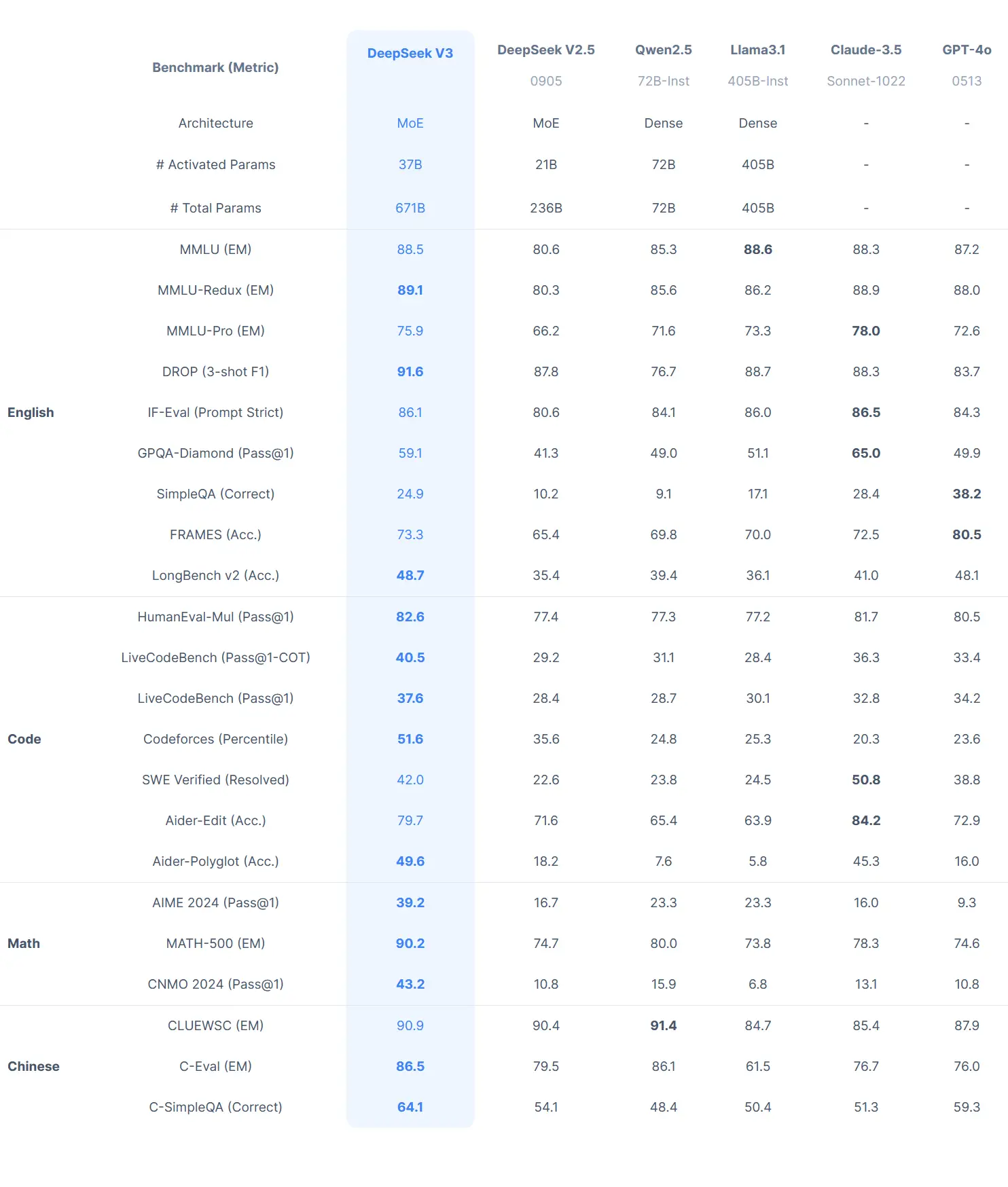 If you are uninterested in being restricted by traditional chat platforms, I highly advocate giving Open WebUI a try and discovering the vast prospects that await you. Open the node's settings, grant access to your Google account, select a title, and insert the text. The open source coding mannequin, exemplified by deepseek ai china Coder and DeepSeek-R1, has democratized entry to advanced AI capabilities, fostering collaboration and customization. Can DeepSeek Coder be used for commercial purposes? The primary ones I have used so far is deepseek coder and dolphin (the largest variant of every). AI models are consistently evolving, and each programs have their strengths. Just some days ago, we were discussing the releases of DeepSeek R1 and Alibaba’s QwQ models that showcased astonishing reasoning capabilities. OpenAI lately unveiled its latest mannequin, O3, boasting vital advancements in reasoning capabilities. The breakthrough of OpenAI o1 highlights the potential of enhancing reasoning to improve LLM. DeepSeek-V3 employs a mixture-of-consultants (MoE) architecture, activating only a subset of its 671 billion parameters during each operation, enhancing computational efficiency. Technical innovations: The mannequin incorporates superior features to enhance efficiency and efficiency. The pretokenizer and training knowledge for our tokenizer are modified to optimize multilingual compression effectivity.
If you are uninterested in being restricted by traditional chat platforms, I highly advocate giving Open WebUI a try and discovering the vast prospects that await you. Open the node's settings, grant access to your Google account, select a title, and insert the text. The open source coding mannequin, exemplified by deepseek ai china Coder and DeepSeek-R1, has democratized entry to advanced AI capabilities, fostering collaboration and customization. Can DeepSeek Coder be used for commercial purposes? The primary ones I have used so far is deepseek coder and dolphin (the largest variant of every). AI models are consistently evolving, and each programs have their strengths. Just some days ago, we were discussing the releases of DeepSeek R1 and Alibaba’s QwQ models that showcased astonishing reasoning capabilities. OpenAI lately unveiled its latest mannequin, O3, boasting vital advancements in reasoning capabilities. The breakthrough of OpenAI o1 highlights the potential of enhancing reasoning to improve LLM. DeepSeek-V3 employs a mixture-of-consultants (MoE) architecture, activating only a subset of its 671 billion parameters during each operation, enhancing computational efficiency. Technical innovations: The mannequin incorporates superior features to enhance efficiency and efficiency. The pretokenizer and training knowledge for our tokenizer are modified to optimize multilingual compression effectivity.
This contrasts with cloud-based mostly models where knowledge is usually processed on external servers, raising privateness concerns. These fashions produce responses incrementally, simulating a process much like how people purpose via issues or ideas. 5. Apply the identical GRPO RL course of as R1-Zero with rule-primarily based reward (for reasoning tasks), but additionally mannequin-based reward (for non-reasoning tasks, helpfulness, and harmlessness). It worked, however I had to contact up issues like axes, grid traces, labels, and so forth. This complete process was significantly quicker than if I had tried to learn matplotlib immediately or tried to find a stack overflow question that happened to have a usable answer. I don’t suppose this system works very nicely - I tried all the prompts within the paper on Claude three Opus and none of them labored, which backs up the concept the bigger and smarter your model, the more resilient it’ll be. Within the paper "Deliberative Alignment: Reasoning Enables Safer Language Models", researchers from OpenAI introduce Deliberative Alignment, a brand new paradigm for coaching safer LLMs. Within the paper "AceMath: Advancing Frontier Math Reasoning with Post-Training and Reward Modeling", researchers from NVIDIA introduce AceMath, a suite of large language models (LLMs) designed for fixing advanced mathematical problems.
It could handle multi-flip conversations, observe complicated instructions. Meanwhile, momentum-based mostly methods can achieve one of the best model quality in synchronous FL. The big Concept Model is skilled to carry out autoregressive sentence prediction in an embedding house. In the paper "Discovering Alignment Faking in a Pretrained Large Language Model," researchers from Anthropic investigate alignment-faking habits in LLMs, the place fashions appear to adjust to instructions but act deceptively to attain their objectives. Edge 459: We dive into quantized distillation for basis models together with an ideal paper from Google DeepMind on this space. Like most belongings you read about on the internet, this isn't something you should dive into blindly. Edge 460: We dive into Anthropic’s recently released mannequin context protocol for connecting knowledge sources to AI assistant. OT knowledge is merged with session occasions right into a single timeline. That is in sharp contrast to humans who operate at multiple levels of abstraction, properly past single phrases, to investigate information and to generate artistic content. Momentum approximation is suitable with safe aggregation in addition to differential privacy, and might be easily built-in in production FL techniques with a minor communication and storage price.
- 이전글The best way to Get (A) Fabulous Deepseek On A Tight Funds 25.02.03
- 다음글гей онлайн 25.02.03
댓글목록
등록된 댓글이 없습니다.