How To Avoid Wasting Money With Deepseek?
페이지 정보

본문
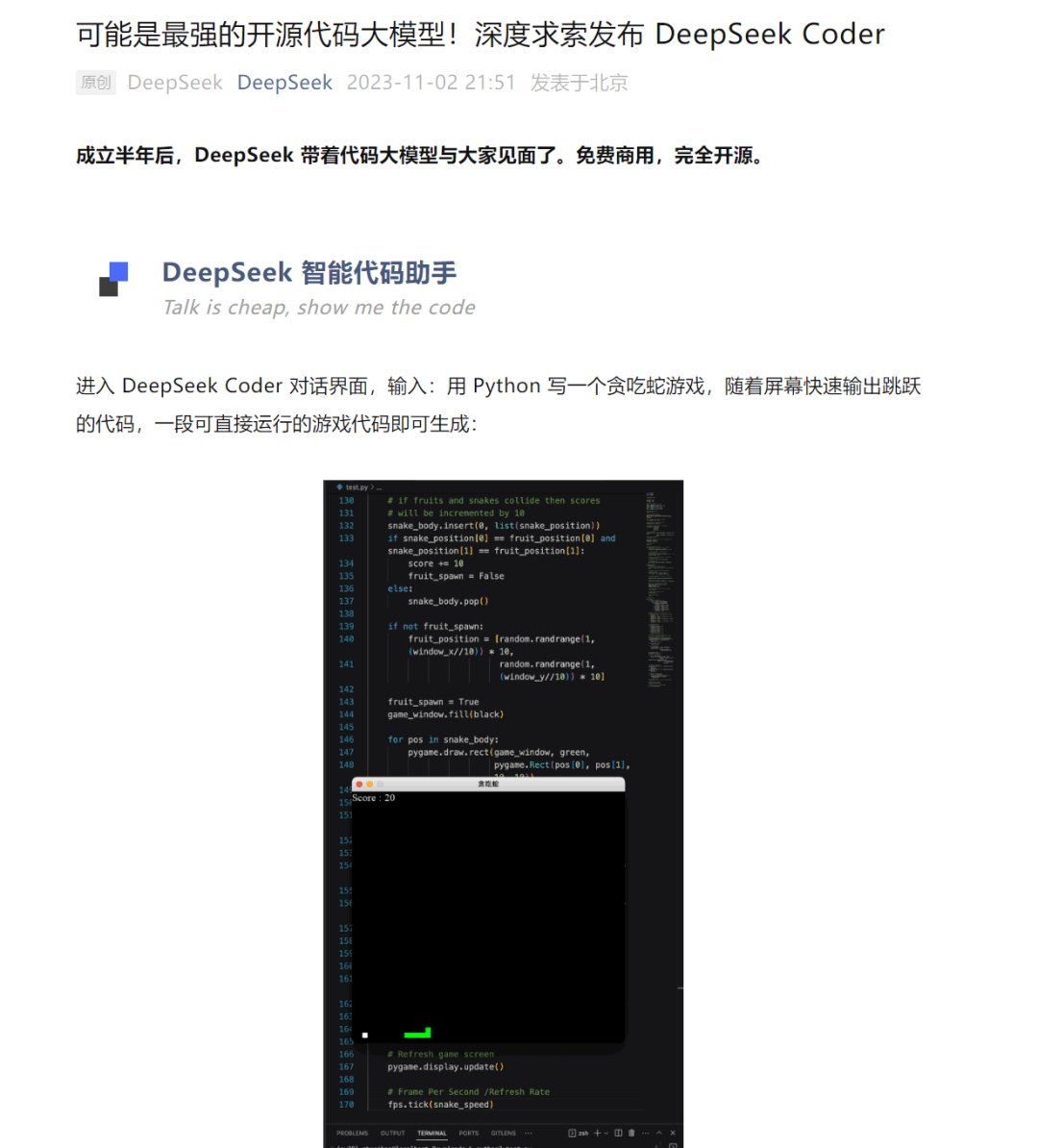 Taiwan's authorities banned using DeepSeek at authorities ministries on security grounds and South Korea's Personal Information Protection Commission opened an inquiry into DeepSeek's use of private information. Hence, ديب سيك after k consideration layers, information can move forward by up to k × W tokens SWA exploits the stacked layers of a transformer to attend info past the window measurement W . 4096, we've a theoretical consideration span of approximately131K tokens. This process is complicated, with an opportunity to have issues at every stage. Our filtering process removes low-quality web knowledge whereas preserving treasured low-useful resource knowledge. While it responds to a prompt, use a command like btop to check if the GPU is getting used efficiently. It appears to be like incredible, and I'll verify it for positive. You will also must be careful to pick a model that might be responsive using your GPU and that may rely greatly on the specs of your GPU.
Taiwan's authorities banned using DeepSeek at authorities ministries on security grounds and South Korea's Personal Information Protection Commission opened an inquiry into DeepSeek's use of private information. Hence, ديب سيك after k consideration layers, information can move forward by up to k × W tokens SWA exploits the stacked layers of a transformer to attend info past the window measurement W . 4096, we've a theoretical consideration span of approximately131K tokens. This process is complicated, with an opportunity to have issues at every stage. Our filtering process removes low-quality web knowledge whereas preserving treasured low-useful resource knowledge. While it responds to a prompt, use a command like btop to check if the GPU is getting used efficiently. It appears to be like incredible, and I'll verify it for positive. You will also must be careful to pick a model that might be responsive using your GPU and that may rely greatly on the specs of your GPU.
 Given the immediate and response, it produces a reward decided by the reward model and ends the episode. We introduce a system prompt (see beneath) to information the model to generate answers within specified guardrails, similar to the work carried out with Llama 2. The prompt: "Always assist with care, respect, and fact. See the installation instructions and different documentation for extra particulars. Check with the official documentation for more. This is more challenging than updating an LLM's data about basic facts, as the model should purpose in regards to the semantics of the modified function relatively than just reproducing its syntax. The reward function is a mix of the preference model and a constraint on policy shift." Concatenated with the original prompt, that textual content is passed to the preference model, which returns a scalar notion of "preferability", rθ. Specifically, we paired a policy model-designed to generate problem options in the type of computer code-with a reward model-which scored the outputs of the coverage model. This reward mannequin was then used to practice Instruct using Group Relative Policy Optimization (GRPO) on a dataset of 144K math questions "related to GSM8K and MATH".
Given the immediate and response, it produces a reward decided by the reward model and ends the episode. We introduce a system prompt (see beneath) to information the model to generate answers within specified guardrails, similar to the work carried out with Llama 2. The prompt: "Always assist with care, respect, and fact. See the installation instructions and different documentation for extra particulars. Check with the official documentation for more. This is more challenging than updating an LLM's data about basic facts, as the model should purpose in regards to the semantics of the modified function relatively than just reproducing its syntax. The reward function is a mix of the preference model and a constraint on policy shift." Concatenated with the original prompt, that textual content is passed to the preference model, which returns a scalar notion of "preferability", rθ. Specifically, we paired a policy model-designed to generate problem options in the type of computer code-with a reward model-which scored the outputs of the coverage model. This reward mannequin was then used to practice Instruct using Group Relative Policy Optimization (GRPO) on a dataset of 144K math questions "related to GSM8K and MATH".
We’re going to cover some theory, clarify how you can setup a locally operating LLM model, after which lastly conclude with the test outcomes. We then prepare a reward model (RM) on this dataset to predict which mannequin output our labelers would favor. Enhanced code era abilities, enabling the mannequin to create new code extra successfully. This submit was more around understanding some basic concepts, I’ll not take this learning for a spin and check out deepseek ai china-coder model. We yearn for growth and complexity - we can't wait to be outdated enough, sturdy enough, capable enough to take on more difficult stuff, but the challenges that accompany it can be unexpected. The researchers plan to extend DeepSeek-Prover's knowledge to more advanced mathematical fields. Usually Deepseek is more dignified than this. While DeepSeek LLMs have demonstrated impressive capabilities, they don't seem to be without their limitations. Reinforcement studying. DeepSeek used a big-scale reinforcement learning method focused on reasoning duties. Showing results on all 3 tasks outlines above.
For each benchmarks, We adopted a greedy search method and re-applied the baseline outcomes utilizing the identical script and environment for truthful comparability. To check our understanding, we’ll carry out a few simple coding tasks, and evaluate the assorted methods in achieving the desired outcomes and likewise present the shortcomings. So this would imply making a CLI that supports multiple strategies of creating such apps, a bit like Vite does, but obviously just for the React ecosystem, and that takes planning and time. Approximate supervised distance estimation: "participants are required to develop novel strategies for estimating distances to maritime navigational aids whereas concurrently detecting them in pictures," the competitors organizers write. We're going to use the VS Code extension Continue to combine with VS Code. Now we want the Continue VS Code extension. Now we set up and configure the NVIDIA Container Toolkit by following these instructions. Now we're prepared to start out hosting some AI fashions. Save the file and click on the Continue icon in the left aspect-bar and you ought to be able to go.
Should you loved this post and you want to receive more info regarding ديب سيك assure visit our web site.
- 이전글Speak "Yes" To These 5 Buy French Bulldogs Tips 25.02.03
- 다음글주소요 - 주소모음 사이트|jusoyo 25.10.23
댓글목록
등록된 댓글이 없습니다.